Introduction
In a time of tightening budgets and increased focus on patient outcomes, predictive Healthcare solutions are increasingly being sought for the benefits they provide on both sides of the Healthcare equation. One common example of a predictive Healthcare solution is screening. Screening is widely used throughout the Healthcare industry to provide early detection of long term conditions and their associated complications. For many conditions, early detection of the condition or potential complications can be beneficial to both the patient and the provider, giving improved outcomes for patients and savings in time and budget for Healthcare providers. However, since screening programs are working within the limits of their capacity, there is a need to identify a patient cohort for whom screening would provide the most benefit. This can be achieved using Population Health Management (PHM) and Artificial Intelligence AI to identify populations at risk of developing the conditions screened for.
It is also important to demonstrate that the costs associated with the screening program are more than adequately offset by the savings from early detection of a condition. Current screening programs may be targeted by age, geographic location etc. By targeting more directly those patients most likely to develop a condition, it is possible to improve detection rates without the need to increase screening rates. Currently, detection rates of non-targeted screening programmes are low, for example, the detection rate of AF is only 0.9% meaning that 111 subjects need to be screened to detect one patient with AF. By using the i5 Health Ai Pre-Diagnosis Predictor AI tool the detection rate for targeted screening has been increased to 24.5% (942 subjects of which 231 had AF). The use of AI to identify patients and the provision of specific service needs leads to a more efficient Healthcare system with less waste.
Methodology
The use of Artificial Intelligence forms the core of a business analysis process providing unique solutions for the Healthcare provider. The process takes the rich data available from the Health service and the specific requirements of the Healthcare provider to define a data set that is used to train the Neural Network. The trained Neural Network then processes the data for the local Health economy to provide a business solution for the Healthcare provider.
The Healthcare provider supplies the initial input to the workflow in the form of a specification of the screening programme and any pre-defined patient cohort parameters. The specification of the screening programme includes the conditions that are to be screened for along with a definition of the set of patients to be considered. Pre-defined patient cohort parameters include limitations to be imposed upon the system output - such as number of patients or balance of patients within the cohort.
Healthcare records are analysed using the requirements set by the Healthcare provider in identifying a target population. Primary Component Analysis is applied to the target population to define the input data set for the neural network.
The workflow diagram shown below covers the stages in producing a patient cohort for screening from the full patient data set through to provision of a patient cohort to the Healthcare provider.
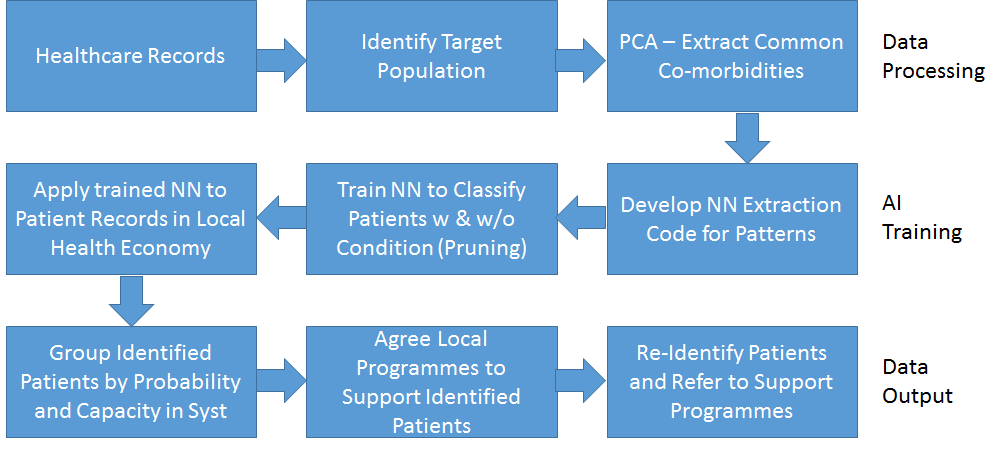
Data Processing
In order to provide a patient cohort for a specific screening service, initial data analysis focuses on patients that have previously received that diagnosis in order to draw out the relevant characteristics. Primary component analysis (PCA) is used to identify the fields and values that have the highest probability of being significant in the cases of other patients developing a condition under investigation.
An input data set is then created containing a record for each patient with a 1/0 (true/false) value for each field/value that was identified as significant during the PCA. The last field of the data set indicates whether the patient has been diagnosed with the condition being investigated.
Before the data can be used for training the network, the input data set has to be balanced and split to allow for validation and to ensure that the output will not be skewed. Balancing the input data set ensures that the network does not unduly favour one outcome due to the nature of the input set. In a typical case the training data set is selected to have an equal number of patients with and without a condition being investigated.
The data set is also split to provide (1) a training data set which the network uses to learn from and (2) a validation data set that is used to prevent over-learning by ensuring that the network provides a satisfactory result for previously unseen data. During training, results for the training and the validation data sets are analysed to ensure that, while training outcomes are improving, the validation outcomes are not deteriorating.
The design of the input data set also requires the size of the data file to be defined. A larger data set will provide improved learning but will also require more learning time. The balance between learning capability and processing time must be considered based on outcome requirements.
Network
The network needed is multi-layered and uses a back propagation algorithm often called a Multilayer Perceptron (MLP).
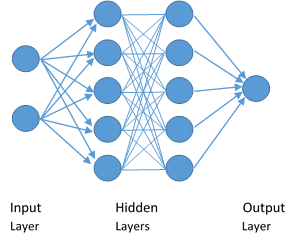
The training data set is applied to the network. As the training continues, the generalisation data set is used to check the progress of the network training. The stopping criteria is set as the point at which the generalisation error is minimised.
Following training, the network to can be analysed to ensure optimisation. Nodes within the network that do not contribute to the output may be pruned.
The trained network and can then be used to analyse the data for all patients in the target cohort as defined by the healthcare provider.
Output
Output from the network is in the form of a percentage probability for each patient. The output probability can be converted to a true/false value with the trigger percentage set taking into account the confidence value of the data set and locally set requirements.
The patient cohort list may be further adjusted based on particular local criteria – for example, focusing on groups that have been found to be likely to have a high number of ‘missing’ patients.